import data from csv file
-
THE POST BELOW IS MORE THAN 5 YEARS OLD. RELATED SUPPORT INFORMATION MIGHT BE OUTDATED OR DEPRECATED
On 01/03/2012 at 00:52, xxxxxxxx wrote:
Hi all, noob question here.
I've posted this already on cgtalk, so sorry if you saw this already.I'd need to import via a python xpresso node, data from a file. This (ascii comma separated) file would be formated as follows, [index, x, y, z, intensity], so the node would take as input the file path and outs the x,y,z as a vector and the intensity as a real.
this is where I am at the moment (the code was with the help of a colleague)
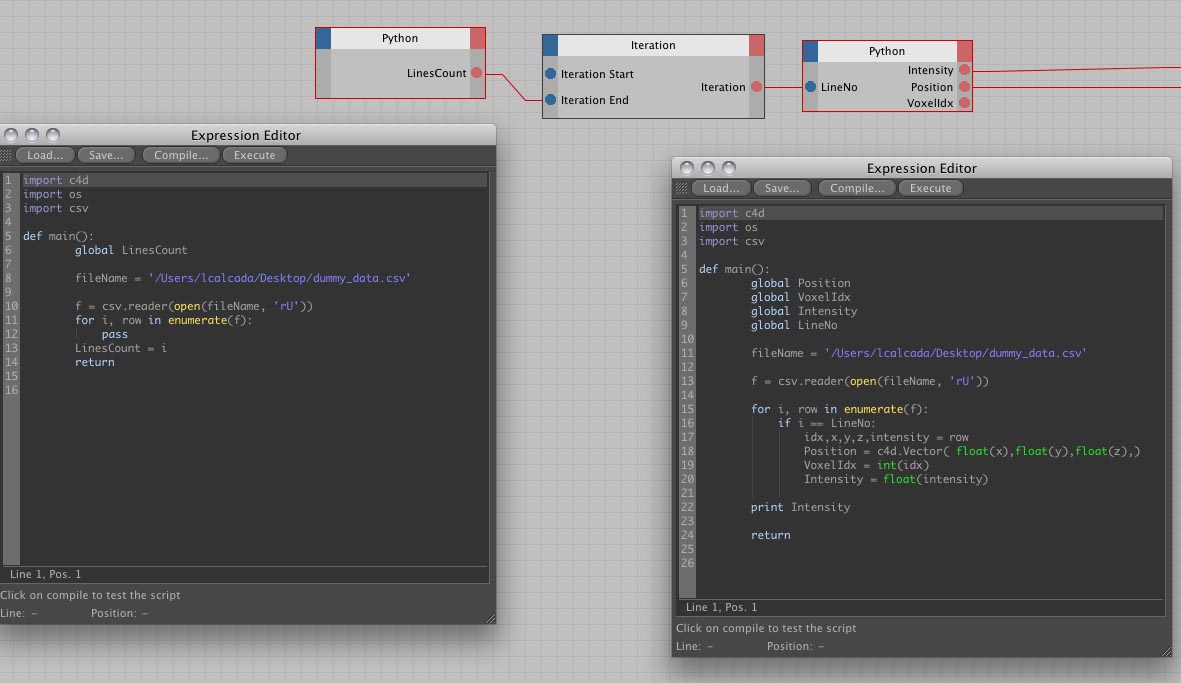
The snippet on the left reads how many lines there's on the file, feeds this in the iterator, which then one by one feeds it to the second python script which then goes one by one line of the file and grabs a index, vector (x,y,z) and intensity.The thing is that i'm not sure this is the most efficient way of doing it. The file I need to work on is over 500000 points.
I'm afraid this might not be the most efficient way. Can anyone point me how if it is, of if there is a smarter/simpler/more efficient way of doing this, being such a simple task?
Thanks so much in advance.
-
THE POST BELOW IS MORE THAN 5 YEARS OLD. RELATED SUPPORT INFORMATION MIGHT BE OUTDATED OR DEPRECATED
On 01/03/2012 at 00:53, xxxxxxxx wrote:
I know the data could be stored all at once as a matrix, but since the node i need to pass the info to accepts only vectors, hence this approach.
Again, maybe I'm thinking wrong.
-
THE POST BELOW IS MORE THAN 5 YEARS OLD. RELATED SUPPORT INFORMATION MIGHT BE OUTDATED OR DEPRECATED
On 01/03/2012 at 04:33, xxxxxxxx wrote:
Hi,
Here are some background information which might help you to make this much faster:
First you call os.open which is (on default) a blocking operation, that means this
here can be a massive slowdown. Instead of using this in main I would use it in the global scope (see example).The function main is triggered on each scene update. That means (due to 2 nodes)
the file is opened by the first node and then opened again per line again by
the second node.import c4d print "I am called once on initialization" #printed if the container of the node was changed def main() : print "Triggered per scene update"Instead of this structure I would cache the entire data in the memory like this:
First Node:
import c4d import csv fp = open("/Users...") _LinesCount = len(list(reader(fp))) #btw, len(list(reader(...))) is a faster way to get the lineno of a csv file, but regard exception handling def main() : global LinesCount LinesCount = _LinesCountSecond Node:
import c4d import csv #best is to handle Exceptions here as well fp = open("/Users...") cached_data = load data and store in global structure def main() : global Position global VoxelIdx global Intensity row = cached_data[LineNo] Position, VoxelIdx, Intensity = rowBtw, to reload the file on frame 0 you might enable the attribute "Reset on Frame 0".
Just a few optimizations which should be much faster. Hope this helps.Cheers, Sebastian
-
THE POST BELOW IS MORE THAN 5 YEARS OLD. RELATED SUPPORT INFORMATION MIGHT BE OUTDATED OR DEPRECATED
On 05/03/2012 at 00:47, xxxxxxxx wrote:
Thank you so much for the help Sebastian,
much appreciated!